Meta’s AI Arriving in Europe: Privateness Disputes Concealing Copyright Considerations – Cyber Tech
Since 22 Might 2024, Meta has notified to European customers of Instagram and Fb – by in-app notifications and emails – an replace of its privateness coverage, linked to the upcoming implementation of synthetic intelligence (AI) applied sciences within the space.
Certainly, the corporate already developed and made out there some AI options and experiences in different components of the world, together with an assistant referred to as “Meta AI” (right here and right here), constructed on a big language mannequin (LLM) referred to as “Llama” (right here and right here), and, in an official assertion, introduced the approaching plan to broaden their use additionally in Europe.
This initiative resulted in some pending privateness disputes, which polarized the controversy. Nonetheless, information seem like only one aspect of the medal and to hide a lot deeper copyright issues. Given the holistic method required by the challenges associated to the development of AI fashions, it’s acceptable to proceed so as, beginning with a broader overview.
The brand new Meta’s privateness coverage
In accordance with the brand new privateness coverage, which can come into impact on 26 June 2024, Meta will course of, particularly, exercise and knowledge offered by customers – together with content material created, like posts, feedback or audio – to develop and enhance AI know-how offered on its merchandise and to 3rd events, enabling the creation of content material like textual content, audio, photos and movies. Respectable pursuits pursuant Article 6(1)(f) of the Common Knowledge Safety Expertise (GDPR) are invoked as authorized foundation.

A complementary part specifies {that a} mixture of sources will probably be used for coaching functions, together with info publicly out there on-line, licensed info from different suppliers and knowledge shared on Meta’s services, with the one express exclusion of personal messages with family and friends.
The privateness coverage of WhatsApp doesn’t appear affected, even when new AI instruments are in improvement additionally for this service. The identical appear to use to the overall phrases of use.
The appropriate to object
The consumer has the correct to object to info shared getting used to develop and enhance AI know-how. For this function, the consumer is required to fill in a web based type accessible from a hyperlink – “proper to object” – positioned on the prime of the privateness coverage (right here, in the intervening time, for Fb and for Instagram). The kinds seem out there solely after the log-in and solely inside EU.
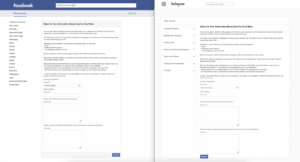
Curiously, failure to offer a motivation, even whether it is requested as necessary, doesn’t appear to undermine the acceptance of the request, which – because the writer was in a position to confirm – is mostly confirmed by electronic mail inside a number of seconds. In any case, such opt-out will probably be efficient solely going ahead and a few information might nonetheless be used if the consumer seems in a picture somebody shared or is talked about in one other consumer’s posts or captions.
The consumer will probably be in a position additionally to submit requests with a view to entry, obtain, right, delete, object or limit any private info from third events getting used to develop and enhance AI at Meta. For this function, the consumer is required to offer prompts that resulted in private info showing and screenshots of associated responses.
The privateness disputes
The talked about notifications apparently adopted a lot of enquiries from the Irish Knowledge Safety Fee (DPC), which slowed down – however didn’t block – the launch of the initiative.
Towards this background, on 4 June 2024, the Norwegian Knowledge Privateness Authority raised doubts concerning the legality of the process.
On 6 June 2024, NOYB, an Austrian non-profit group specializing in industrial privateness points on a European stage, filed complaints in entrance of the authorities of 11 European international locations (Austria, Belgium, France, Germany, Greece, Italy, Eire, the Netherlands, Norway, Poland and Spain). It alleged a number of violations of the GDPR, together with the shortage of legit pursuits, the vagueness of the phrases “synthetic intelligence know-how”, the deterrence within the train of the correct of object, the failure to offer clear info, the non-ability to correctly differentiate between topics and information and the irreversibility of the processing. Consequently, it requested a preliminary cease of any processing actions pursuant Article 58(2) GDPR and the beginning of an urgency process pursuant Article 66 GDPR.
On 10 June 2024, Meta launched an official assertion underlining the larger transparency than earlier coaching initiatives of different corporations and declaring that Europeans ought to “have entry to – or be correctly served by – AI that the remainder of the world has” and that “will probably be ill-served by AI fashions that aren’t knowledgeable by Europe’s wealthy cultural, social and historic contributions”.
On 14 June 2024, the Irish DPC reported the choice by Meta to pause its plans of coaching throughout the EU/EEA following intensive engagement between the authority and the corporate.
On the identical day, NOYB responded by emphasizing the potential for Meta to implement AI know-how in Europe by requesting legitimate consent from customers, as an alternative of an opt-out. Furthermore, it underlined that, as much as that time, no official change has been made to Meta’s privateness coverage that will make this dedication legally binding.
At current, subsequently, the case seems at a standstill.
The copyright issues
In the meantime, past the privateness points, authors and performers worldwide – the driving power behind such providers – are protesting to the brand new AI coverage of Meta. Many threaten to go away the platforms, even when abandoning the social capital accrued on these providers might symbolize a serious impediment. Others suggest using applications which undertake totally different strategies to impede the evaluation of the works and the coaching of AI applied sciences, reminiscent of Nightshade and Glaze. Furthermore, platforms which might be overtly antagonistic to AI are gaining consideration, reminiscent of Cara, which doesn’t at the moment host AI artwork, makes use of a detection know-how to this function and implements “NoAI” tags supposed to discourage scraping.
Even different web service suppliers are at the moment dealing with comparable points and had to offer sure clarifications. As an illustration, Adobe, after some uncertainty on the interpretation of its up to date phrases of use which offered for a license to entry content material by each automated and handbook strategies, has not too long ago clarified (right here and right here) that their clients’ content material won’t be used to coach any generative AI instruments and confirmed its dedication to proceed innovation to guard content material creators.
Final month, as an alternative, Open AI, which is defendant in some pending copyright infringement claims, revealed its method to information and AI, affirming the significance of a brand new social contract for content material within the AI age and saying the event by 2025 of a Media Supervisor, which “will allow creators and content material homeowners to inform [OpenAI] what they personal and specify how they need their works to be included or excluded from the coaching” (see, for an evaluation on this weblog, Jütte).
All this seems to be a part of a rising lack of belief of authors and performers surrounding tech corporations and their AI instruments, in addition to a robust demand for ensures. Whereas the event of AI applied sciences may end up in essential inventive devices, the query of the honest consideration of the pursuits of authors and performers of the underlying works, together with their remuneration by digital media and the sustainability of inventive professions, stays open.
To flee this interregnum, a brand new stability is required. Maybe it’s time to restart from copyright fundamentals and, particularly, who the system is meant to guard. If the reply will probably be authors, then just a few superstars and even the remaining overwhelming majority? The danger is mental works to be thought of simply information – as this affair appears to emphasise – and authors and performers to be mislabeled as mere content material creators.

Whose Consent? – Verfassungsblog – Cyber Tech

Auf der Suche nach der verlorenen Zeit – Verfassungsblog – Cyber Tech

Measuring Compliance and the Selections of UNCLOS Dispute Settlement Our bodies – EJIL: Speak! – Cyber Tech
About The Author
admin
Azeem Rajpoot, the author behind This Blog, is a passionate tech enthusiast with a keen interest in exploring and sharing insights about the rapidly evolving world of technology. With a background in Blogging, Azeem Rajpoot brings a unique perspective to the blog, offering in-depth analyses, reviews, and thought-provoking articles. Committed to making technology accessible to all, Azeem strives to deliver content that not only keeps readers informed about the latest trends but also sparks curiosity and discussions. Follow Azeem on this exciting tech journey to stay updated and inspired.
